参考:https://zhuanlan.zhihu.com/p/649366179
https://www.anjhon.top/llms-mac-local-rag
llama-cpp-python 的安装
llama.cpp是ggml这个机器学习库的衍生项目,专门用于Llama系列模型的推理。llama.cpp和ggml均为纯C/C++实现,针对Apple Silicon芯片进行优化和硬件加速,支持模型的整型量化 (Integer Quantization): 4-bit, 5-bit, 8-bit等。社区同时开发了其他语言的bindings,例如llama-cpp-python,由此提供其他语言下的API调用。
GitHub 仓库:https://github.com/abetlen/llama-cpp-python
apple silicon 安装教程参考:https://llama-cpp-python.readthedocs.io/en/latest/install/macos/
安装脚本:
pip uninstall llama-cpp-python -y
CMAKE_ARGS="-DGGML_METAL=on" pip install -U llama-cpp-python --no-cache-dir
pip install 'llama-cpp-python[server]'
|
- 安装 llama-cpp-python,编译时启动 metal 平台加速(针对不同后端硬件使用不同硬件加速策略,例如 cuda 加速,cpu 加速等)
- 额外安装
server 依赖,从而让你能在本地运行 LLaMA 模型并开启一个 API 服务接口(像 OpenAI 的 ChatGPT 一样通过 HTTP 调用)。
安装量化的模型
llama-cpp 只支持 gguf 格式的量化模型,可以直接下载量化好的模型,或者自己手动量化。
这个仓库:https://huggingface.co/TheBloke,会专门提供量化好的模型。
例如可以选择 deepseek-llm-7b-chat.Q5_K_S.gguf 这个模型。
安装好之后,使用下面命令运行与测试大模型
python3 -m llama_cpp.server --model gguf模型路径 --n_gpu_layers 100
|
Note: If you omit the --n_gpu_layers 100 then CPU will be used,这表示加载到 GPU(metal)上的层数
然后点击 http://localhost:8000/docs# 可以看到如下:

运行如下代码可以测试这个模型,来写一首诗
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "llama",
"messages": [
{"role": "user", "content": "请帮我写一首诗"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json()["choices"][0]["message"]["content"])
|
构建 RAG
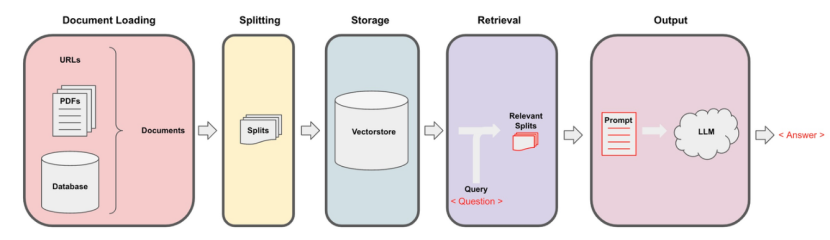
本实验旨在构建一个基于检索增强技术的大模型问答系统。通过结合外部知识库的高效检索能力与大语言模型的强大生成能力,系统能够在面对复杂或专业性较强的问题时,快速检索相关知识片段并生成准确、连贯的答案。
RAG 系统的基本流程通常包括三个阶段:
-
知识库构建。这一步主要包括从各类文档中加载原始数据,对文本进行清洗和切分(splitting),将其划分为适合处理的语义片段。随后,使用嵌入模型(如 Sentence-BERT、text-embedding-ada-002 等)将文本转化为向量形式,并存入向量数据库中(如 FAISS、Milvus 等),形成可查询的外部知识库。
-
检索。当用户提出问题时,系统会将用户查询编码为向量,并与知识库中的文本向量进行相似度匹配,检索出与查询语义最相关的若干文档或段落。这一过程显著提高了系统对特定领域信息的覆盖能力,使得模型能够访问超出其预训练知识范围的最新或专业内容。
-
生成。检索到的相关文段会与用户的问题一并输入至大语言模型中(如 LLaMA、Mistral、ChatGLM 等),模型在参考相关知识的基础上生成语义连贯、上下文一致的回答。
运行 llama.cpp server
python3 -m llama_cpp.server --model gguf模型路径 --n_gpu_layers 100
|
运行以后就会在某个端口,运行一个大语言模型的服务器,会得到一个 openai_api_base: http://localhost:8000/v1
构建知识库
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("data/中国科学技术大学研究生学籍管理实施细则.pdf")
pages = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter= RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 150,)
all_splits = splitter.split_documents(pages)
from langchain.vectorstores import FAISS
embedding =HuggingFaceEmbeddingsMPS("shibing624/text2vec-base-chinese")
vectorstore = FAISS.from_documents(documents=all_splits, embedding=embedding)
|
这里对 pdf 文件,先加载,读取句子后,使用 RecursiveCharacterTextSplitte 将句子分段(分片),然后投影到 embedding 维度。注意:每个句子对应一个嵌入向量。
检索
query = pair["question"]
true_answer = pair["answer"]
result_simi=vectorstore.similarity_search(query,k=3)
context = "".join([x.page_content for x in result_simi]);
try:
model_answer = llm_chain.run({"context": context,"query": query})
|
这里 result_simi 为一个 document 列表,即 段落列表,首先使用 query 找到最相似的 3 个语段,然后将这些语段,作为上下文传递给 llm。
生成
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=512)
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template = """
请基于以下内容简洁回答,不使用 Markdown 格式,也不要加标题、列表、代码块或换行符。只输出纯文本。
{context}
问题:
{query}
"""
prompt = PromptTemplate(template=template, input_variables=["context" ,"query"])
llm_chain = LLMChain(prompt=prompt, llm=chat_model , llm_kwargs = {"temperature":0, "max_tokens":512})
from tqdm import tqdm
results = []
for pair in tqdm(qa_pairs):
query = pair["question"]
true_answer = pair["answer"]
result_simi=vectorstore.similarity_search(query,k=3)
context = "".join([x.page_content for x in result_simi]);
try:
model_answer = llm_chain.run({"context": context,"query": query})
results.append({
"question": query,
"true_answer": true_answer,
"model_answer": model_answer
})
except Exception as e:
results.append({
"question": query,
"true_answer": true_answer,
"model_answer": f"Error: {str(e)}"
})
|
完整代码
from langchain.embeddings.base import Embeddings
from sentence_transformers import SentenceTransformer
import torch
class HuggingFaceEmbeddingsMPS(Embeddings):
def __init__(self, model_name):
self.device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
self.model = SentenceTransformer(model_name, device=self.device)
def embed_documents(self, texts):
return [self.model.encode(text) for text in texts]
def embed_query(self, text):
return self.model.encode(text)
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("data/中国科学技术大学研究生学籍管理实施细则.pdf")
pages = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter= RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 150,)
all_splits = splitter.split_documents(pages)
from langchain.vectorstores import FAISS
embedding =HuggingFaceEmbeddingsMPS("shibing624/text2vec-base-chinese")
vectorstore = FAISS.from_documents(documents=all_splits, embedding=embedding)
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=512)
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template = """
请基于以下内容简洁回答,不使用 Markdown 格式,也不要加标题、列表、代码块或换行符。只输出纯文本。
{context}
问题:
{query}
"""
prompt = PromptTemplate(template=template, input_variables=["context" ,"query"])
llm_chain = LLMChain(prompt=prompt, llm=chat_model , llm_kwargs = {"temperature":0, "max_tokens":512})
import pandas as pd
df = pd.read_excel("data/问答对.xlsx")
qa_pairs = [{"question": q, "answer": a} for q, a in zip(df["问"], df["答"])]
from tqdm import tqdm
results = []
for pair in tqdm(qa_pairs):
query = pair["question"]
true_answer = pair["answer"]
result_simi=vectorstore.similarity_search(query,k=3)
context = "".join([x.page_content for x in result_simi]);
try:
model_answer = llm_chain.run({"context": context,"query": query})
results.append({
"question": query,
"true_answer": true_answer,
"model_answer": model_answer
})
except Exception as e:
results.append({
"question": query,
"true_answer": true_answer,
"model_answer": f"Error: {str(e)}"
})
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def get_similarity(true_answer, model_answer, embedder=embedding):
embs = embedder.model.encode([true_answer, model_answer], convert_to_numpy=True)
return cosine_similarity([embs[0]], [embs[1]])[0][0]
for r in results:
if "Error" not in r["model_answer"]:
r["similarity"] = get_similarity(r["true_answer"], r["model_answer"])
else:
r["similarity"] = 0.0
result_df = pd.DataFrame(results)
result_df.to_excel("results2.xlsx", index=False)
average_similarity = result_df["similarity"].mean()
print(f"Average similarity: {average_similarity:.4f}")
|